Difference between val &var ?
Scala allows you to define variables using val or var. The variables defined using val are immutable, meaning cant be changed once initialized. On the other hand, variables defined using var are mutable and can be changed even after initialization.
Note that the immutability applies to the variable but not to the instance to which it refers to.
For Example : val buffer = new StringBuffer(), here we cannot change what buffer refers to however we can change the instance of StringBuffer. On the other hand if instance is string, even it cannot be changed.
Note that the immutability applies to the variable but not to the instance to which it refers to.
For Example : val buffer = new StringBuffer(), here we cannot change what buffer refers to however we can change the instance of StringBuffer. On the other hand if instance is string, even it cannot be changed.
Difference between val & def ?
def gets evaluated on every function call and creates a new function instead of using the same instance of the function. On the other hand val gets evaluated when defined. There is another flavor called lazy val that gets evaluated on the first function call.
def evaluates on every call, so performance could be worse then with val for multiple calls. You'll get the same performance with a single call. And with no calls you'll get no overhead from def, so you can define it even if you will not use it in some branches
def evaluates on every call, so performance could be worse then with val for multiple calls. You'll get the same performance with a single call. And with no calls you'll get no overhead from def, so you can define it even if you will not use it in some branches
Rich Classes
Scala treats everything as Objects, meaning we can call methods on literals like we can methods on object. For example: 1.to(3)
Scala treats Scala.Int as Java Int, but when user calls method like to() on int Scala applies intWrapper() method to convert int to scala.runtime.RichInt and invokes to() method on it.
Other Rich classes like RichInt, RichDouble, RichBoolean
Scala treats Scala.Int as Java Int, but when user calls method like to() on int Scala applies intWrapper() method to convert int to scala.runtime.RichInt and invokes to() method on it.
Other Rich classes like RichInt, RichDouble, RichBoolean
Multiple Assignments
Multiple assignment in Scala comes in very handy, when you want to return multiple values for a function call.
For example, we have to return vehicle id, type, model. One way to do it in Java is to create a VehicleInfo class and return the object.
While in Scala, we can make use of multiple assignment.
For example, we have to return vehicle id, type, model. One way to do it in Java is to create a VehicleInfo class and return the object.
While in Scala, we can make use of multiple assignment.
Example:
def getVehicleInfo(vehicleId: Int) = {
/* Logic */
(12345, "Sport","SX4")
}
Default imports in Scala
Scala imports default packages in following order:
Predef object contains types, implicit conversions, and methods that are commonly used in Scala. It also contains aliases for Scala collections.
- java.scala.lang
- scala
- scala.Predef
Predef object contains types, implicit conversions, and methods that are commonly used in Scala. It also contains aliases for Scala collections.
"==" behavior in Scala
Scala handles "==" differently from Java. Java handles "==" differently for primitive types Vs Objects. For primitive types "==" means value based comparison where as for objects it is identity based. So if a and b are int then a == b results in true when both the values are same. However, if they're references to objects, the result is true only if both references are pointing to the same instance. Java equals() method provides value based comparison for objects.
On the other hand, in Scala "==" represents value based comparison no matter what type it is. ==() implementation uses Java's equals() method. In order to perform identity based comparison we can use eq() method.
On the other hand, in Scala "==" represents value based comparison no matter what type it is. ==() implementation uses Java's equals() method. In order to perform identity based comparison we can use eq() method.
Example:
val str1 = "string"
val str2 = "string"
val str3 = new String("string")
println (str1 == str2) // true
println (str1 == str3) // true
println (str1 eq str2) // true
println (str1 eq str3) //false
Access Modifiers
- Scala defaults the access to public when not specified.
- Scala's protected is accessible only by derived classes. Furthermore, the derived class can access the protected members only on its own type.
- In Scala the encapsulation is at class level ( similar to Java). However you can restrict it to current instance
- To make members private or protected, just mention respective keyword before the name
'Implicit' in Scala
When the compiler finds an expression of the wrong type for the context, it will look for an implicit Function value of a type that will allow it to typecheck. So if an A is required and it finds a B, it will look for an implicit value of type B => A in scope.
Implicit can be used in following locations:
Implicit can be used in following locations:
- Extending or adding a Scala-style collection
- Adapting or extending an object (“pimp my library” pattern)
- Use to enhance type safety by providing constraint evidence
- To provide type evidence (type-classing)
- For Manifests
Collections in Scala
Sets
Creating a set: val set1 = Set(1,2,3) // This creates a Set[Int], we wont be using the keyword 'New' for defining collections in Scala as they are internally handled by apply() method.
A Set will hold the elements at most once. If we need to merge two sets say set1 and set 2 : val concatSet = set1 ++ set2.
If you need to compare two sets and find the common ones then: val commonSet = set1 ** set 2.
Map
Map is used to store Key-Value pairs. val mapExample = Map("A" -> 1, "AB" -> 2, "B" -> 3).
Some operations on Map:
List
Unlike Set and Map that has both mutable and immutable implementations, List has only immutable implementation. val simpleList = List("A","AB","B","BA"). List is indexed sequence so can be accessed using index [0, simpleList.length - 1].
Some operations on List
To get the first element of a List: simpleList.head
To get the all the elements except first from list: simpleList.tail
To prefix an element to the list: "ABC" :: simpleList
Prefixing two lists: listNew ::: simpleList
To check whether all elements in the list satisfy some condition we can use forAll() on the other hand if we want to know if any element satisfying the criteria we can use exists().
To find length of all elements in a list: simpleList.foldLeft(0) { (accumulator, element) => accumulator + element.length }
* IF a method name ends with (:) the target of the call is the instance that follows the operator. Similarly there are other operators like +,-,! & ~. The unary + maps over to call to unary_+(), and so on.
Also, take notice of your requirements and use the data-structure suitable for your use-case. You want to build a stack? That's a List. You want to index a list? That's a Vector. You want to append to the end of a list? That's again a Vector. You want to push to the front and pull from the back? That's a Queue. You have a set of things and want to check for membership? That's a Set. You have a list of things that you want to keep ordered? That's a SortedSet.
Creating a set: val set1 = Set(1,2,3) // This creates a Set[Int], we wont be using the keyword 'New' for defining collections in Scala as they are internally handled by apply() method.
A Set will hold the elements at most once. If we need to merge two sets say set1 and set 2 : val concatSet = set1 ++ set2.
If you need to compare two sets and find the common ones then: val commonSet = set1 ** set 2.
Map
Map is used to store Key-Value pairs. val mapExample = Map("A" -> 1, "AB" -> 2, "B" -> 3).
Some operations on Map:
- To fetch value for a key: mapExample.get("A")
- if you want to get keys starting with "A" : mapExample filterKeys ( _ startsWith "A")
- filter on values and return if value is 2: mapExample filter { case (key, value) => value == 2 }
- To add an element to the Map we can use update method this would return a new map with the existing and new element. mapExample.update("BA" -> 4) which is equivalent to mapExample("BA") = 4
List
Unlike Set and Map that has both mutable and immutable implementations, List has only immutable implementation. val simpleList = List("A","AB","B","BA"). List is indexed sequence so can be accessed using index [0, simpleList.length - 1].
Some operations on List
To get the first element of a List: simpleList.head
To get the all the elements except first from list: simpleList.tail
To prefix an element to the list: "ABC" :: simpleList
Prefixing two lists: listNew ::: simpleList
To check whether all elements in the list satisfy some condition we can use forAll() on the other hand if we want to know if any element satisfying the criteria we can use exists().
To find length of all elements in a list: simpleList.foldLeft(0) { (accumulator, element) => accumulator + element.length }
* IF a method name ends with (:) the target of the call is the instance that follows the operator. Similarly there are other operators like +,-,! & ~. The unary + maps over to call to unary_+(), and so on.
Also, take notice of your requirements and use the data-structure suitable for your use-case. You want to build a stack? That's a List. You want to index a list? That's a Vector. You want to append to the end of a list? That's again a Vector. You want to push to the front and pull from the back? That's a Queue. You have a set of things and want to check for membership? That's a Set. You have a list of things that you want to keep ordered? That's a SortedSet.
Pattern Matching
Below example demonstrates pattern matching with lists covering 2 special cases: _* & @.
_* is used to refer rest elements that are of least concern to us while matching. For example in the third case statement, we are interested in a list with red, blue as first 2 elements and we dont care remaining elements so we used _*.
@: If we need to reference the remaining matching elements, we can place a variable name (like otherFruits) before a special @ symbol as shown in the below code.
def processItems(items: List[String]) { items match {
case List("apple", "ibm") => println("Apples and IBMs")
case List("red", "blue", "white") => println("Stars and Stripes...")
case List("red", "blue", _*) => println("colors red, blue, ... ")
case List("apple", "orange", otherFruits @ _*) =>
println("apples, oranges, and " + otherFruits) }
}
processItems(List("apple", "ibm"))
processItems(List("red", "blue", "green"))
processItems(List("red", "blue", "white"))
processItems(List("apple", "orange", "grapes", "dates"))
_* is used to refer rest elements that are of least concern to us while matching. For example in the third case statement, we are interested in a list with red, blue as first 2 elements and we dont care remaining elements so we used _*.
@: If we need to reference the remaining matching elements, we can place a variable name (like otherFruits) before a special @ symbol as shown in the below code.
def processItems(items: List[String]) { items match {
case List("apple", "ibm") => println("Apples and IBMs")
case List("red", "blue", "white") => println("Stars and Stripes...")
case List("red", "blue", _*) => println("colors red, blue, ... ")
case List("apple", "orange", otherFruits @ _*) =>
println("apples, oranges, and " + otherFruits) }
}
processItems(List("apple", "ibm"))
processItems(List("red", "blue", "green"))
processItems(List("red", "blue", "white"))
processItems(List("apple", "orange", "grapes", "dates"))
Regular Expressions
Scala supports regular expression through classes in scala.util.matching package.
val pattern = "(S|s)cala".r // upon calling r method on string, scala implicitly converts the String to RichString and invokes that method to a instance of Regex.
val str = "Scala is Scalable and cool"
println(pattern findFirstIn str) // to find the first match in the string. findAllIn() method is used to find all occurrences in str.
println( "cool".r replaceFirstIn (str, "awesome")) // replaceFirstIn replaces the first occurrence new replace string.
val pattern = "(S|s)cala".r // upon calling r method on string, scala implicitly converts the String to RichString and invokes that method to a instance of Regex.
val str = "Scala is Scalable and cool"
println(pattern findFirstIn str) // to find the first match in the string. findAllIn() method is used to find all occurrences in str.
println( "cool".r replaceFirstIn (str, "awesome")) // replaceFirstIn replaces the first occurrence new replace string.
Classes in Scala
Lets compare the creation of classes in Java and Scala to understand how Scala works.
|
Scala Example:
|
Lets highlight the difference between both:
- In the Java version, we explicitly defined the field and method for the property year and wrote an explicit constructor.
- In Scala, the parameter to the class took care of defining that field and writing the accessor method.
- Scala rolls the primary constructor into the class definition and pro- vides a concise way to define fields and corresponding methods
- Scala automatically made the class public—everything in Scala that you don’t mark private or protected defaults to public.
- We declared year as a val, so Scala defines number as a private final field and creates a public method year( ) to help us fetch that value.
- Since we declared make as a var, Scala defines a private field named make and gives us a public getter and setter for it.
- If we don’t declare a parameter as a val or var, then Scala creates a private field and a private getter and setter for it. However, that parameter is not accessible from outside the class.
- You can have auxiliary constructors to take additional parameters than primary constructor. The first statement within an auxiliary constructor is required to be a call to either the primary constructor or another auxiliary constructor.
- Extending from a base class in Scala is similar to extending in Java except for two restrictions: method overriding requires the override key- word, and only the primary constructor can pass parameters to the base constructor.
Singleton Object
- It is a class that has only one instance. We use singletons to represent objects that act as a central point of contact for certain operations such as database access, object factories, and so on. Creating singleton objects in Scala is very simple. You create them using the keyword object instead of class. Since you can’t instantiate a singleton object, you can’t pass parameters to the primary constructor.
- We can access the singleton (the only instance) by its name. Once you define a singleton, its name represents the single instance of the singleton object. You can pass around the singleton to functions like you pass around instances in general.
- Scala also allows you to create a singleton that is connected to a class. Such a singleton will share the same name as a class name and is called a companion object. The corresponding class is called a companion class.
Static in Scala
- Scala does not have static fields and methods. However, Scala fully supports class-level operations and proper- ties. This is where companion objects come in.
- So the Static methods would reside in companion object.
Type Inference in Scala
Static typing, or compile-time type checking, helps you define and verify interface contracts at compile time. Scala, unlike some of the other statically typed languages, does not expect you to provide redundant type information. You don’t have to specify a type in most cases, and you certainly don’t have to repeat it. At the same time, Scala will infer the type and verify proper usage of references at compile time. We can query and get the type of variable using method .getClass() on the variable.
Scala differs from Java when it is handling generics.
Scala differs from Java when it is handling generics.
import java.util._
val list1 = new ArrayList[Int]
val list2 = new ArrayList
list2 = list1 // This will throw error during compiling because, list2 is of type ArrayList[Nothing]
Reason is 'Nothing' is the subclass of all classes in Scala, so we can't treat instance of base class as an instance of derived class. In order, to define an ArrayList without specifying type we can make use of 'Any' type. Any is the base / super class of all classes. Any is an abstract class with the following methods: !=(), ==(), asInstanceOf( ), equals( ), hashCode( ), isInstanceOf( ), and toString( ). However, Scala doesn’t allow, by default, assigning a collection of arbitrary type instances to a reference of a collection of Any instances. So the assignment ArrayList[Any] = ArrayList[Int] will also throw compilation Error.
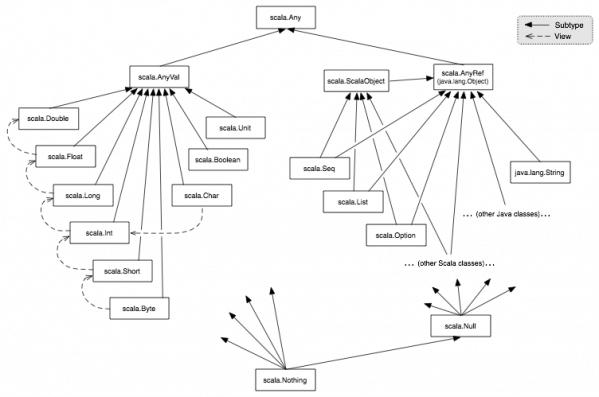
he direct descendants of Any are AnyVal and AnyRef. AnyVal serves as a base for all types in Scala that map over to the primitive types in Java—for example, Int, Double, and so on. On the other hand, AnyRef is the base for all reference types. Although AnyVal does not have any additional methods, AnyRef contains the methods of Java’s Object such as notify( ), wait( ), and finalize( )
he direct descendants of Any are AnyVal and AnyRef. AnyVal serves as a base for all types in Scala that map over to the primitive types in Java—for example, Int, Double, and so on. On the other hand, AnyRef is the base for all reference types. Although AnyVal does not have any additional methods, AnyRef contains the methods of Java’s Object such as notify( ), wait( ), and finalize( )
Option Type
Option is the Scala's way of specifying non existence of object. For example, in pattern matching, the result of match can be an object or may be non existence. So returning null to represent non existence is is problematic in two ways. First, the intent that you actually expect nonexistence of a result is not expressed explicitly. Second, there is no way to force the caller of your function to check for nonexistence (null). Scala wants you to clearly specify your intent that sometimes you do actually expect to give no result. Scala achieves this in a type-safe manner using the Option[T] type.
Return type inference
If method is defined with equals (=) sign then Scala will infer the type of return value/ref otherwise it will assume as void.
def one { 9 } // return type of this definition of method is considered as void
def two = { 9 } // while return type here is considered as Int.
def one { 9 } // return type of this definition of method is considered as void
def two = { 9 } // while return type here is considered as Int.
Passing Variable arguments
We can pass variable number of arguments to a method by specifying * after the member type definition. Example:
def Sum (num: Int*) = num.foldLeft(0)(_+_)
def Sum (num: Int*) = num.foldLeft(0)(_+_)
Covariance and Contra-variance
Covariance: Ability to send collection of subclass instances to collection of base class.
Contra-variance: Ability to send collection of superclass instances to the collection of derived class.
By default, Scala doesn't allow either of them. One way to beat around this issue of covariance is to use a special syntax while defining the method in super class.
The syntax is : [T<:Super_Class_name]
Contra-variance: Ability to send collection of superclass instances to the collection of derived class.
By default, Scala doesn't allow either of them. One way to beat around this issue of covariance is to use a special syntax while defining the method in super class.
The syntax is : [T<:Super_Class_name]
|
Solution
|
Currying
Currying in Scala transforms a function that takes more than one parameter into a function that takes multiple parameter lists. Instead of writing a method that takes one parameter list with multiple parameters, write it with multiple parameter lists with one parameter each (you may have more than one parameter in each list as well). That is, instead of def foo(a: Int, b: Int, c: Int) {}, write it as def foo(a: Int)(b: Int)(c: Int) {}
Partial Function in Scala
Partial function is a function when not all parameters required for that function are provided. We can use partial function to generate intermediate functions that take only the subset of parameters that haven't been passed earlier.
Example:
def log(date: Date, message: String) {}
val logWithDate = log(new Date, _: String)
logWithDate("message1")
logWithDate("message2")
Example:
def log(date: Date, message: String) {}
val logWithDate = log(new Date, _: String)
logWithDate("message1")
logWithDate("message2")
Exposing the possibility of Failure in Type
Scala provides Try[T] monad to expose the possibility of failure in type T.
For example in the following code, we are not always sure that the connection to database will always be success.
def connectToDatabase(): Connection = { }
To handle the possibility of failure, we can redefine the method as follows:
def connectToDatabase(): Try[Connection] = { }
Now, Try[Connection] has 2 possibilities - Success(connection) or Failure(exception). this can be captured using pattern matching or higher-order functions like flatMap or using for comprehension.
The Try[T] is similar to Option[T] or Either[T, S], in that it is a monad potentially holding a value of some type. However, it has been specifically designed to either hold a value or some throwable object. Where an Option[T] could either be a value (i.e. Some[T]) or no value at all (i.e.None), Try[T] is a Success[T] when it holds a value and otherwise Failure[T], which holds an exception. Failure[T] holds more information that just a plain None by saying why the value is not there. In the same time, you can think of Try[T] as a special version ofEither[Throwable, T], specialized for the case when the left value is a Throwable.
For example in the following code, we are not always sure that the connection to database will always be success.
def connectToDatabase(): Connection = { }
To handle the possibility of failure, we can redefine the method as follows:
def connectToDatabase(): Try[Connection] = { }
Now, Try[Connection] has 2 possibilities - Success(connection) or Failure(exception). this can be captured using pattern matching or higher-order functions like flatMap or using for comprehension.
The Try[T] is similar to Option[T] or Either[T, S], in that it is a monad potentially holding a value of some type. However, it has been specifically designed to either hold a value or some throwable object. Where an Option[T] could either be a value (i.e. Some[T]) or no value at all (i.e.None), Try[T] is a Success[T] when it holds a value and otherwise Failure[T], which holds an exception. Failure[T] holds more information that just a plain None by saying why the value is not there. In the same time, you can think of Try[T] as a special version ofEither[Throwable, T], specialized for the case when the left value is a Throwable.
Exposing the Possibility of latency
Scala has a Future[T] monad to handle exceptions and latency in computation. Future is used when asynchronous behavior is needed to combat the impact of latency. Future[T] is a trait that has onComplete( callback: Try[T] => Unit) method that runs after the computation is over. If you want to handle success then use onSuccess() or if you want to see failures then you can use onFailure(). The onComplete, onSuccess, and onFailure methods have result type Unit, which means invocations of these methods cannot be chained
Important to know:
Some combinators on futures that would make programming safe are recoverWith(), recover(), fallbackTo()
Promise is a companion type that allows you to complete a Future by putting a value into it. This can be done exactly once. Once a Promisehas been completed, it’s not possible to change it any more. To complete a Future other than through a Promise – the apply method on Future is just a nice helper function that shields you from this.
- If the computation has not yet completed, we say that the Future is not completed.
- If the computation has completed with a value or with an exception, we say that the Future iscompleted.
- When a Future is completed with a value, we say that the future was successfully completed with that value.
- When a Future is completed with an exception thrown by the computation, we say that theFuture was failed with that exception.
- In the event that multiple callbacks are registered on the future, the order in which they are executed is not defined. In fact, the callbacks may be executed concurrently with one another. However, a particular ExecutionContext implementation may result in a well-defined order.
Important to know:
Some combinators on futures that would make programming safe are recoverWith(), recover(), fallbackTo()
- Also, look for async { .. await{..}..} feature that helps to get T in place of Future[T]
- Futures are designed to be used with callable, which returns a result.
- Executors contain factories and utility methods for concurrent classes. [ Handles the Thread pools]
Promise is a companion type that allows you to complete a Future by putting a value into it. This can be done exactly once. Once a Promisehas been completed, it’s not possible to change it any more. To complete a Future other than through a Promise – the apply method on Future is just a nice helper function that shields you from this.
Iterables & Observables
Both are used for stream of data.
Iterables: (synch - pull based)
This is a base scala trait for all collections that define a iterator method to step through one by one of elements in collections.
trait Iterable[T] { def iterator():Iterator[T] }
Iterators are the data structures that allow to iterate over sequence of elements. They have a has next method to check if there is a next element in the collection and next method returns the next element.
trait Iterator[T] { def hasNext: Boolean ; def next(): T }
Observables: (async - push based)
trait Observable[T] {
def subscribe (observer: Observer[T]): Subscription
}
type Observer[T] = (Throwable => Unit, () => Unit, T => Unit ) is transformed to a trait with 3 functions
trait Observer[T] {
def onError (error: Throwable): Unit
def onCompleted (): Unit
def onNext (value: T): Unit
}
In Observable the observer that subscribes acts as the callback with three functions onError, onCompleted & onNext and can be called many times unlike Future.
Also the Subscription returned upon subscribe is a trait with unsubscribed and isSubscribed methods.
trait Subscription {
def unsubscribe(): Unit
def isUnsubscribed: Boolean
}
Iterables: (synch - pull based)
This is a base scala trait for all collections that define a iterator method to step through one by one of elements in collections.
trait Iterable[T] { def iterator():Iterator[T] }
Iterators are the data structures that allow to iterate over sequence of elements. They have a has next method to check if there is a next element in the collection and next method returns the next element.
trait Iterator[T] { def hasNext: Boolean ; def next(): T }
Observables: (async - push based)
trait Observable[T] {
def subscribe (observer: Observer[T]): Subscription
}
type Observer[T] = (Throwable => Unit, () => Unit, T => Unit ) is transformed to a trait with 3 functions
trait Observer[T] {
def onError (error: Throwable): Unit
def onCompleted (): Unit
def onNext (value: T): Unit
}
In Observable the observer that subscribes acts as the callback with three functions onError, onCompleted & onNext and can be called many times unlike Future.
Also the Subscription returned upon subscribe is a trait with unsubscribed and isSubscribed methods.
trait Subscription {
def unsubscribe(): Unit
def isUnsubscribed: Boolean
}
Higher-order functions
Functions that take other functions as parameters are called higher-order functions. They reduce code duplication, increase reusability and make code concise. In Scala, you can create functions within functions, assign them to references, and pass them around to other functions. Scala internally deals with these so-called function values by creating them as instances of special classes. So, in Scala, function values are really objects.
Traits
A trait is like an interface with a partial implementation. The vals and vars you define and initialize in a trait get internally implemented in the classes that mix the trait in.
trait Friend {
val name: String
def listen() = println("Your friend " + name + " is listening")
}
val named name is the abstract member and the classes that mix friend should implement it.
Usage: class Human( val name:String) extends Friend or class Dog (val name:String) extends Animal with Friend. Also Scala allows to define specific instance of a class to mix with trait for example consider class Cat (val name:String) extends Animal, but it doesn't mix-in the trait Friend. Let's say you want to implement Dizzy (Cat) as a friend to listen, then:
val Dizzy = new Cat("Dizzy") with Friend
Abstract override: when a trait is extending an abstract class with an abstract method, and then the method definition should be prefixed with abstract override.
By using the keyword override, we are telling Scala that we are providing an implementation of a known method from the base class. At the same time, we are saying that the actual final “terminal” implementation for this method will be provided by the class that mixes in the trait.
trait Friend {
val name: String
def listen() = println("Your friend " + name + " is listening")
}
val named name is the abstract member and the classes that mix friend should implement it.
Usage: class Human( val name:String) extends Friend or class Dog (val name:String) extends Animal with Friend. Also Scala allows to define specific instance of a class to mix with trait for example consider class Cat (val name:String) extends Animal, but it doesn't mix-in the trait Friend. Let's say you want to implement Dizzy (Cat) as a friend to listen, then:
val Dizzy = new Cat("Dizzy") with Friend
Abstract override: when a trait is extending an abstract class with an abstract method, and then the method definition should be prefixed with abstract override.
By using the keyword override, we are telling Scala that we are providing an implementation of a known method from the base class. At the same time, we are saying that the actual final “terminal” implementation for this method will be provided by the class that mixes in the trait.
Type Conversions
Implicit type conversion by simply marking the method as implicit, and Scala will automatically pick it up if it is present in the current scope (visible through current imports or present in the current file).
Actors in Scala
Actor model represent objects and their interactions resembling human organizations and built on the laws of physics.
An actor’s purpose is the processing of messages, and these messages were sent to the actor from other actors (or from outside the actor system). The piece which connects sender and receiver is the actor’s mailbox: each actor has exactly one mailbox to which all senders enqueue their messages. Enqueuing happens in the time-order of send operations, which means that messages sent from different actors may not have a defined order at runtime due to the apparent randomness of distributing actors across threads. Sending multiple messages to the same target from the same actor, on the other hand, will enqueue them in the same order. There are different mailbox implementations to choose from, the default being a FIFO: the order of the messages processed by the actor matches the order in which they were enqueued.
Once an actor terminates, i.e. fails in a way which is not handled by a restart, stops itself or is stopped by its supervisor, it will free up its resources, draining all remaining messages from its mailbox into the system’s “dead letter mailbox” which will forward them to the EventStream as DeadLetters. The mailbox is then replaced within the actor reference with a system mailbox, redirecting all new messages to the EventStream as DeadLetters.
When subordinate fails, supervisor has following options:
/user: The Guardian Actor:
The actor which is probably most interacted with is the parent of all user-created actors, the guardian named "/user". Actors created using system.actorOf() are children of this actor. This means that when this guardian terminates, all normal actors in the system will be shutdown, too. It also means that this guardian’s supervisor strategy determines how the top-level normal actors are supervised. Since Akka 2.1 it is possible to configure this using the setting akka.actor.guardian-supervisor-strategy, which takes the fullyqualified class-name of a SupervisorStrategyConfigurator. When the guardian escalates a failure, the root guardian’s response will be to terminate the guardian, which in effect will shut down the whole actor system.
/: The Root Guardian :
The root guardian is the grand-parent of all so-called “top-level” actors and supervises all the special actors mentioned in Top-Level Scopes for Actor Paths using the SupervisorStrategy.stoppingStrategy, whose purpose is to terminate the child upon any type of Exception. All other throwables will be escalated . . . but to whom? Since every real actor has a supervisor, the supervisor of the root guardian cannot be a real actor. And because this means that it is “outside of the bubble”, it is called the “bubble-walker”. This is a synthetic ActorRef which in effect stops its child upon the first sign of trouble and sets the actor system’s isTerminated status to true as soon as the root guardian is fully terminated (all children recursively stopped).
Life Cycle Monitoring (Lifecycle Monitoring in Akka is usually referred to as DeathWatch):
In contrast to the special relationship between parent and child described above, each actor may monitor any other actor. Since actors emerge from creation fully alive and restarts are not visible outside of the affected supervisors, the only state change available for monitoring is the transition from alive to dead. Monitoring is thus used to tie one actor to another so that it may react to the other actor’s termination, in contrast to supervision which reacts to failure. Lifecycle monitoring is implemented using a Terminated message to be received by the monitoring actor, where the default behavior is to throw a special DeathPactException if not otherwise handled. In order to start listening for Terminated messages, invoke ActorContext.watch(targetActorRef). To stop listening, invoke ActorContext.unwatch(targetActorRef). One important property is that the message will be delivered irrespective of the order in which the monitoring request and target’s termination occur, i.e. you still get the message even if at the time of registration the target is already dead. Monitoring is particularly useful if a supervisor cannot simply restart its children and has to terminate them, e.g. in case of errors during actor initialization. In that case it should monitor those children and re-create them or schedule itself to retry this at a later time. Another common use case is that an actor needs to fail in the absence of an external resource, which may also be one of its own children. If a third party terminates a child by way of the system.stop(child) method or sending a PoisonPill, the supervisor might well be affected.
Actor is an object with identity, has a behavior and only interacts asynchronously using message passing. This is implemented using Actor trait. Actor trait has one method to define that is Receive that returns a partial function from Any to Unit. It describes the response of an actor to a message. The receive method doesn't return anything as the caller would have long gone by, due to asynchronous message passing.
In the above example Receive method returns a partial function that increments the count when "incr" is received as input.
This Actor doesn't return any answer back hence it doesn't exhibit a state-full behavior. To make this Actor state-full we need to enable another actor to find out what the value of counter is. Therefore, Actor can send message to the addresses ( ActorRef) they know. Sending message from one actor to other picks up sender's address implicitly. The "!" signifies send and pronounced as til in Scala Actor model. (See Example 3)
More functionality of Actors
Actors can create more actors, or change behavior this execution is done by ActorContext. Changing the behavior of an actor actually means modifying the Receive method. See the become method of ActorContext (See Example 4)
Advantages of defining the actor as above is:
Simple Actor Application: ( See Example 5)
An actor’s purpose is the processing of messages, and these messages were sent to the actor from other actors (or from outside the actor system). The piece which connects sender and receiver is the actor’s mailbox: each actor has exactly one mailbox to which all senders enqueue their messages. Enqueuing happens in the time-order of send operations, which means that messages sent from different actors may not have a defined order at runtime due to the apparent randomness of distributing actors across threads. Sending multiple messages to the same target from the same actor, on the other hand, will enqueue them in the same order. There are different mailbox implementations to choose from, the default being a FIFO: the order of the messages processed by the actor matches the order in which they were enqueued.
Once an actor terminates, i.e. fails in a way which is not handled by a restart, stops itself or is stopped by its supervisor, it will free up its resources, draining all remaining messages from its mailbox into the system’s “dead letter mailbox” which will forward them to the EventStream as DeadLetters. The mailbox is then replaced within the actor reference with a system mailbox, redirecting all new messages to the EventStream as DeadLetters.
When subordinate fails, supervisor has following options:
- Resume the subordinate, keeping its accumulated internal state
- Restart the subordinate, clearing out its accumulated internal state
- Stop the subordinate permanently
- Escalate the failure, thereby failing itself
/user: The Guardian Actor:
The actor which is probably most interacted with is the parent of all user-created actors, the guardian named "/user". Actors created using system.actorOf() are children of this actor. This means that when this guardian terminates, all normal actors in the system will be shutdown, too. It also means that this guardian’s supervisor strategy determines how the top-level normal actors are supervised. Since Akka 2.1 it is possible to configure this using the setting akka.actor.guardian-supervisor-strategy, which takes the fullyqualified class-name of a SupervisorStrategyConfigurator. When the guardian escalates a failure, the root guardian’s response will be to terminate the guardian, which in effect will shut down the whole actor system.
/: The Root Guardian :
The root guardian is the grand-parent of all so-called “top-level” actors and supervises all the special actors mentioned in Top-Level Scopes for Actor Paths using the SupervisorStrategy.stoppingStrategy, whose purpose is to terminate the child upon any type of Exception. All other throwables will be escalated . . . but to whom? Since every real actor has a supervisor, the supervisor of the root guardian cannot be a real actor. And because this means that it is “outside of the bubble”, it is called the “bubble-walker”. This is a synthetic ActorRef which in effect stops its child upon the first sign of trouble and sets the actor system’s isTerminated status to true as soon as the root guardian is fully terminated (all children recursively stopped).
Life Cycle Monitoring (Lifecycle Monitoring in Akka is usually referred to as DeathWatch):
In contrast to the special relationship between parent and child described above, each actor may monitor any other actor. Since actors emerge from creation fully alive and restarts are not visible outside of the affected supervisors, the only state change available for monitoring is the transition from alive to dead. Monitoring is thus used to tie one actor to another so that it may react to the other actor’s termination, in contrast to supervision which reacts to failure. Lifecycle monitoring is implemented using a Terminated message to be received by the monitoring actor, where the default behavior is to throw a special DeathPactException if not otherwise handled. In order to start listening for Terminated messages, invoke ActorContext.watch(targetActorRef). To stop listening, invoke ActorContext.unwatch(targetActorRef). One important property is that the message will be delivered irrespective of the order in which the monitoring request and target’s termination occur, i.e. you still get the message even if at the time of registration the target is already dead. Monitoring is particularly useful if a supervisor cannot simply restart its children and has to terminate them, e.g. in case of errors during actor initialization. In that case it should monitor those children and re-create them or schedule itself to retry this at a later time. Another common use case is that an actor needs to fail in the absence of an external resource, which may also be one of its own children. If a third party terminates a child by way of the system.stop(child) method or sending a PoisonPill, the supervisor might well be affected.
Actor is an object with identity, has a behavior and only interacts asynchronously using message passing. This is implemented using Actor trait. Actor trait has one method to define that is Receive that returns a partial function from Any to Unit. It describes the response of an actor to a message. The receive method doesn't return anything as the caller would have long gone by, due to asynchronous message passing.
In the above example Receive method returns a partial function that increments the count when "incr" is received as input.
This Actor doesn't return any answer back hence it doesn't exhibit a state-full behavior. To make this Actor state-full we need to enable another actor to find out what the value of counter is. Therefore, Actor can send message to the addresses ( ActorRef) they know. Sending message from one actor to other picks up sender's address implicitly. The "!" signifies send and pronounced as til in Scala Actor model. (See Example 3)
More functionality of Actors
Actors can create more actors, or change behavior this execution is done by ActorContext. Changing the behavior of an actor actually means modifying the Receive method. See the become method of ActorContext (See Example 4)
Advantages of defining the actor as above is:
- State change is Explicit
- State is scoped to current behavior.
Simple Actor Application: ( See Example 5)
- Messages can only be send to known addresses.
- Messages are the only way to interact with Actors
- Actors completely independent agents of computation.
- All actors run fully concurrently.
- Processing one message is the atomic unit of execution, this has the benefits of synchronous methods but blocking is replaced by enqueueing the message.
- 'loggingReceive' can be used to log every message received. Its a library in Akka.
- The order in which the messages are processed is random. To achieve some order, we have to define a third actor that is coordinating the actions for rest two.
- Prefer immutable data structures since they can be shared and no problem in sending them across thread boundaries.
- Prefer context.become to model different states of actors, with data local to behavior.
- Don't leak Actor's internal state to the code which runs asynchronously because that breaks Actor model Encapsulation.
// Example 1 type receive = PartialFunction[Any,Unit] trait Actor { implicit val self:ActorRef // holds the reference of its own implicit val context: ActorContext // defines the execution context that can be used to change the behavior of an Actor def sender: ActorRef // in receiving Actor this signifies the reference of sender def receive : receive def preStart() {} def preRestart(cause: Throwable, message: Option[Any]) {} def freshInstance(): Option[Actor] = None def postRestart(cause: Throwable) {} def postStop() {} } abstract class ActorRef { def ! (msg: Any)(implicit sender: ActorRef = Actor.noSender): Unit def tell (msg: Any, sender: ActorRef) = this.!(msg)(sender) } trait ActorContext { def become (behavior: receive, discardOld: Boolean = true) : Unit def unbecome(): Unit def actorOf( p: Props, name: String): ActorRef def stop (a: ActorRef): Unit ... } // Example 2: class Counter extends Actor { var count = 0 def receive = { case "incr" => count += 1 } } // Example 3: class Counter extends Actor { var count = 0 def receive = { case "incr" => count += 1 case ("get", customer: ActorRef) => customer ! count // taking advantage of sender method in actor that has reference to sender this stmt can be modified as below case "get" => sender ! count } } // Example 4 class Counter extends Actor { def counter(n: Int): receive = { case "incr" => context.become(counter(n + 1)) case "get" => sender ! n } def receive = counter(0) } // Example 5: class main extends Actor { val counter = context.actorOf(Props[Counter], "counter") counter ! "incr" counter ! "incr" counter ! "get" def receive = { case count: Int => println("Count is "+ count) context.stop(self) } }
Concurrency Vs Parallelism
Concurrency means that two or more tasks are making progress even though they might not be executing simultaneously.
Parallelism on the other hand arise when the execution can be truly simultaneous.
Parallelism on the other hand arise when the execution can be truly simultaneous.
Asynchronous Vs Synchronous
A method call is considered synchronous if the caller cannot make progress until the method returns a value or throws an exception. On the other hand, an asynchronous call allows the caller to progress after a finite number of steps, and the completion of the method may be signalled via some additional mechanism (it might be a registered callback, a Future, or a message).
Blocking Vs Non-Blocking
Blocking is when the delay of one thread can indefinitely delay some of the other threads.. If a thread holds on to the resource indefinitely (for example accidentally running an infinite loop) other threads waiting on the resource can not progress. In contrast, non-blocking means that no thread is able to indefinitely delay others
Sealed Trait
A sealed trait can be extended only in the same file as its declaration. use sealed traits (or sealed abstract class) if the number of possible subtypes is finite and known in advance.
Example:
sealed Trait Answer
case class yes extends Answer
case class No extends Answer
Example:
sealed Trait Answer
case class yes extends Answer
case class No extends Answer
Thread Pools
Cached: Cached is where you have of N threads where N is usually set to number of processors initially allocated for a task. If more threads are needed they can be created and added to the pool to use in the program. If thread is idle they go back to the pool. This results in poor performance as we end up creating threads and adding to the pool on fly.
Fixed: Fixed is where we have fixed thread pool
Scheduled: Creates threads at regular intervals as scheduled.
Fork/Join: Similar to cache but has little higher overhead. Not ideal for small callbacks. Good for recursive callbacks.
Fixed: Fixed is where we have fixed thread pool
Scheduled: Creates threads at regular intervals as scheduled.
Fork/Join: Similar to cache but has little higher overhead. Not ideal for small callbacks. Good for recursive callbacks.
